The Dell/EMC merger, IBM and co storage revenues decline, … Traditional IT vendors are under attack! What is going on? What’s the bigger picture? How can they recover? I’ll be trying here to answer these questions and suggest some less “simplistic” answers.
We see several major trends which shape our life:
- Most data is consumed and generated by mobile devices
- Applications move to a SaaS based data-consumption model
- Everyone from Retailers, Banks, to Governments depend on data based intelligence to stay competitive
- We are on the verge of the IoT revolution with billions of sensors generating more data
New companies prefer using office 365 or Salesforce.com in the cloud and avoid installing and maintaining local exchange servers, ERP or CRM platforms, and are relieved from investing capital on hardware or software. If you are a twenty or even a hundred-employee firm, there’s no reason to own any servers – do it all in the cloud. But at the same time many organizations depend on their (exponentially growing) data and home-grown apps and are not going to ship it to Amazon anytime soon.
Enterprise IT is becoming very critical to the business. Let’s assume you are the CIO of an insurance company. If you don’t provide a slick and responsive mobile app and tiered pricing based on machine learning of driver records, someone else will, and will disrupt your business, i.e. the “Uber” effect. This forces enterprises to borrow cloud-native and SaaS concepts for on premise deployments, and design around agile and micro-services architecture. These new methodologies impose totally different requirements from the infrastructure, and have caught legacy enterprise software and hardware vendors unprepared.

The challenge for current IT vendors and managers is how do they transform from providing hardware/system solutions for the old application world (exchange, SharePoint, oracle, SAP, ..) which is now migrating to SaaS models, to become a platform/solutions provider for the new agile and data intensive applications which matters most for the business. Some analysts attribute EMC and IBM storage revenue decline to “Software Defined Storage” or Hyper-Converged Infrastructure, Well … it may have had some impact, but the big strategic challenge they have is the Data Transformation.
The above trends impact data in three dimensions: Locality, Scalability, and Data Awareness. As we go mobile and globally distributed, data locality (silos) is becoming a burden, with more data we must address scalability, complexity, and lower the overall costs. To serve the business we must be able to find relevant data in huge data piles, draw insights faster, and make sure it is secured, forcing us to build far more data aware systems.
New solutions have been designed for the cloud and replace traditional enterprise storage, as illustrated in the diagram below.
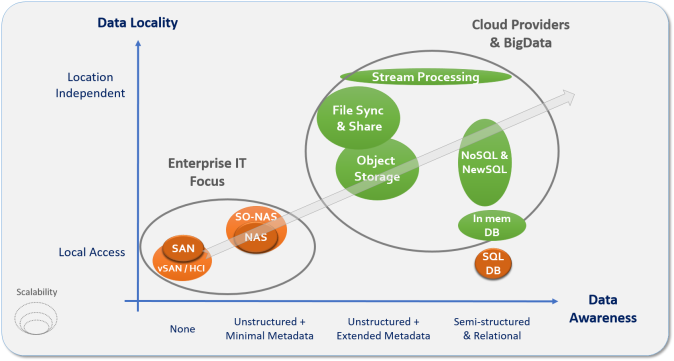
We used to think of Cloud as IaaS (Infrastructure as a service), and had our Private IaaS Clouds using VMware or now OpenStack. But developers no longer care about infrastructure, they want data/computation services and APIs. Cloud Providers acknowledge that and have been investing most of their energy in the last few years in technologies which are easier to use, more scalable and distributed, and in gaining deeper data awareness.
Google developed new databases like Spanner which can span globally and handle semi-structured data consistently (ACID), new data streaming technologies (Dataflow), object storage technologies, Etc. Amazon is arming itself with fully integrated scale-out data services stack including S3 (Object), DynamoDB (NoSQL), Redshift (DW), Kinesis (Streaming), Aroura (Scale-out SQL), Lambda (Notifications), CloudWatch. And Microsoft is not standing still with new services like Azure Data Lake, and is shifting developers from MS SQL to a scale-out database engines.
What’s common to all those new technologies is the design around commodity servers, direct attached high-density disk enclosures or SSD, and fast networking. They implement highly efficient and data aware low-level disk layouts to optimize IOs and search performance, and don’t need a lot of the SAN, vSAN/HCI, or NAS baggage and features, resiliency, consistency, and virtualization is handled at higher levels.
Cloud data services have self-service portals and APIs and are used directly by the application developers, eliminating any operational overhead, no need to wait for IT in order to provision infrastructure for new applications, we consume services and pay per use.
Latest stats show that the majority of Big Data projects are done in the cloud, mainly due to the simplicity. And majority of the on premise deployments are not considered successful, in some cases have negative ROI (due to human resource drain, lots of pro-services, and expensive software licenses). So as long as you’re not concerned about storing your data in the cloud, it would be simpler and cheaper.
EMC, IBM, Dell, and HP have been building is the same non data aware legacy storage model, just slightly better. Many of the new entrants in the all flash, scale-out vSAN, Scale-out NAS, and hyper converged (HCI) are basically going after the same old resource intensive application world with somewhat improved efficiency and scalability. But they do not cater for the new world (read my post on cloud-native apps).
HP has Vertica which is good but a point solution. EMC has Pivotal with several elements of the stack. Many are partial and not too competitive, and they lack the overall integration. IBM has the richest stack including Softlayer, BigInsights, and the latest Cleaversafe acquisition, but not yet in an integrated fashion, and they need to prove they can be as agile and cost effective as the cloud guys.
They can build a platform using open source projects. The challenge is those are usually point solutions, not robust, need to be managed and installed individually, need to add glue logic and sort out dependencies. Most lack the required usability, security, compliance, or management features needed for the enterprise, those issues must be addressed to make it a viable platform. We need things to be integrated just like Amazon is using S3 to backup DynamoDB, Kinesis as a front end to S3, RedShift or DynamoDB, and Lambda as S3 events handler. Vendors may need to shift some focus from their IaaS and OpenStack efforts (IT orientation), to Micro-services, PaaS, and SaaS (DevOps Orientation) with modern, self-service, integrated, and managed data services.
There is still a huge market for on premise IT, many organizations like banks, healthcare, telco, large retailers, etc. have lots of data and computation needs and would not trust Amazon with it. Many Enterprise users are concerned about security and compliance, or are guided by national regulations, and would prefer to stay on premise. Not all Amazon users are happy with the bill they get at the end of the month, especially when they are heavy users of data and services.
But today cloud providers deliver significantly better efficiency than what IT can offer to the business units. If that won’t change we will see more users flowing to the cloud, or clouds coming to the users. Amazon and Azure are talking to organizations about building on premise clouds inside the enterprise, basically out-sourcing the IT function altogether.
Enterprise IT vendors and managers should better wake up soon, take actions, and stop whining about public clouds, or some of them will be left in the cold.

